做预测性维护快八年了,经手的工厂少说也有二十家。说实话,我越来越不信那些PPT上漂亮的准确率曲线。
去年在一家汽配厂,我们部署了一套基于振动的算法,离线测试的时候,故障检出率99.2%,虚警不到1%。简直完美。结果上线第一个月就出了笑话——一台关键磨床主轴抱死,系统一声没吭。事后复盘,发现训练数据里全是稳定工况下的磨损特征,但实际崩坏前,振动频谱突然变“干净”了。对,变干净了。裂纹一次性扩展,没给模型反应时间。
这事儿让我郁闷了很久。也突然意识到,我们太迷恋算法本身,却忘了预测性维护真正的战场在数据定义。
特征提取:别再只盯 RMS 了
大多数教科书会告诉你,时域指标(RMS、峰值、峭度)是基础。没错,它们是基础。但仅靠这些,你连轴承早期点蚀都抓不住。
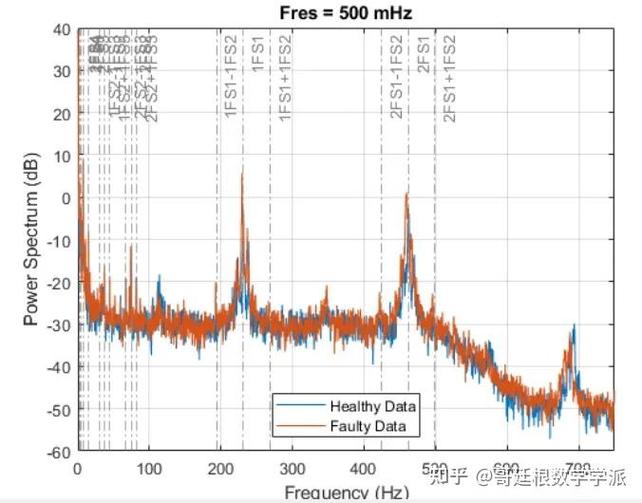
我在一家风电场的齿轮箱上做过对比。常规RMS阈值报警,往往等到振动值翻倍才触发,那时候内圈滚道已经剥落得不成样子。而通过包络谱分析,在调制频率处抓到第一个小尖峰的时候,拆开看才只有针尖大的麻点。
这里插一句——很多人问用哪个特征库好,我没有固定答案。取决于你的设备、转速、甚至润滑脂品牌。✅ 我的习惯是:每接手一个新项目,一定要做一次特征相关性暴力穷举,把几十个特征全部算出来,画热力图,看哪些跟劣化趋势真正单调相关。虽然费时间,但比直接用别人现成的特征子集靠谱十倍。
数据标注的坑:谁在定义“故障”?

说到这个我就来气。
有次去一家泵厂,他们自己标的数据。拆机记录写着“轴承故障”,但实际是保持架断裂引发的次生损伤,根本原因却是对中偏差。算法训练出来后,对类似频谱的报警都指向了轴承,结果维修工换了三次轴承都没修好——直到我趴在地上用激光对中仪一打,才发现轴偏移了0.3毫米。
这就是标签噪音。你以为的“故障”可能只是个表象。所以我现在的信条是:没有根本原因分析的标签,就是毒药。💡 宁可用少量但经过RCA验证的样本,也别贪多。
问:那到底需要多少样本才能训练一个可靠的预测性维护算法?
答:这问题我被问过无数次。答案让人不舒服——看情况。如果故障模式单一且物理机理明确,比如不对中产生的二倍频特征,可能几十组数据就能收敛。但对复杂裂纹扩展,尤其是变速变载工况,没有几千个真实劣化点的积累,模型学到的大概率是偏差。我更倾向用物理模型+数据驱动的混合方法:用运动方程生成基础故障响应,再用现场数据做迁移学习。效果强过纯靠堆数据。
运维决策闭环:算法只是扳手,不是上帝
另一个极端是,认为预测性维护算法能精确到天。早期我也这么天真过。给客户承诺“剩余寿命预测误差不超过10%”,结果被现实狠狠教育。
有一次,算法预测某台冲压机齿轮还剩30天寿命。厂里排了15天后的停机窗口。结果第八天齿轮就崩了,全厂停产36小时。责任人指着我的鼻子骂。我不敢反驳,因为模型没有纳入那几天的临时超负荷生产。
从那以后,我说话谨慎多了。我会在输出里加上置信区间和工况修正系数。更重要的是,推动建立运维决策闭环:把算法输出当成建议,而不是圣旨。维修工程师的现场判断、生产计划的柔性窗口、备件库存深度,必须一起参与决策。❗预测性维护的“算法”,本质是一个不断修正的动态系统,不是一锤子买卖。
问:小企业没有大数据,预测性维护算法能用吗?
答:当然能,但路子不同。别碰深度学习,那是数据饕餮。从基于规则的专家系统切入,结合简单的统计过程控制(SPC)。例如监测振动总量,设置自适应报警线——根据最近30天的均值动态调整。再配合定期巡检的经验,就能避免大部分突发停机。我就用这种朴素方法帮一家只有五台数控的小厂,把意外停机减少了七成。所以说,算法不是越新越好,是越合适越好。
这两年工业互联网平台都在宣传“一键部署预测性维护”。我试过几个,哈哈,一言难尽。模型漂移、边缘算力不足、采样率对不上,问题多得要命。真正落地的项目,背后都是成堆的脏活累活:传感器标定、数据清洗、多源对时、工况分割……
有时候深夜盯着监控屏,看着那条微微上扬的峭度趋势线,会突然觉得——好的预测性维护算法,不是让你高枕无忧,而是让你更清醒地知道下一个风险可能藏在哪里。这就够了。
免责声明:文章内容来自互联网,本站仅作为分享,不对其真实性负责,如有侵权等情况,请与本站联系删除。
转载请注明出处:预测性维护算法:我被那个“几乎完美”的模型坑惨了 https://www.dachanpin.com/a/tg/58253.html