上个月,一台减速机突然抱死。拆开一看,齿轮碎得跟饼干渣似的——厂长脸都绿了。其实,两个月前振动频谱里就有了征兆,怪我们没当回事。这破事儿让我窝火了好几天。预测性维护算法,听起来高大上,说白了就是给设备“算命”,但不是靠玄学,是靠数据。
很多厂子还在搞事后维修,坏了再修,或者定期拆换。结果呢?不是过度维护浪费钱,就是突然停机亏大钱。说实话,搞工业的谁没被设备故障坑过?那种半夜被叫起来抢修的感觉,真不是滋味。💡 预测性维护算法就是提前告诉你:这家伙下礼拜可能要崴脚,悠着点。
但算法这玩意儿,水很深。我见过有人花几十万上AI系统,最后还不如老师傅看一眼油尺。为什么?因为没搞懂数据本质。下面拆开了揉碎了讲。
振动分析:预测性维护的“听诊器”
大部分旋转机械——泵、电机、压缩机——出毛病前都有振动异常。记着,振动信号是设备的“心电图”。但心电图怎么读?不是直接塞给AI。你得先做特征提取。时域、频域、时频域,三座大山。⛰️ 时域指标像峭度、峰峰值,对冲击敏感;频域里看轴承特征频率,剥落、磨损都对应特定频率边带。

问题是,现场信号脏得离谱。电磁干扰、负载波动、共振尖峰……有一回我拿到数据,明明轴承坏了,频谱上却全是齿轮啮合频率的谐波。后来才发现是传感器装歪了。❗所以,数据预处理是命门:带通滤波、包络解调、同步平均,这些常规操作比模型重要十倍。
不过话说回来,你费劲搞了百来个特征,算法一跑反而不如只用RMS值。这就涉及下一个坑。
从特征到模型:别再一头扎进深度学习
现在一提预测性维护,张口LSTM、Transformer。打住!我踩过这个坑。用深度学习搞振动信号分类,看似炫酷,实际呢?训练数据少得可怜,标签全是正常样本,故障就那么几次,过拟合严重。你调参调到崩溃,上线一测,报警洪水滔天,全是误报。✅ 踏踏实实用传统机器学习:随机森林、XGBoost、SVM,结合PCA降维,解释性强,还不容易翻车。
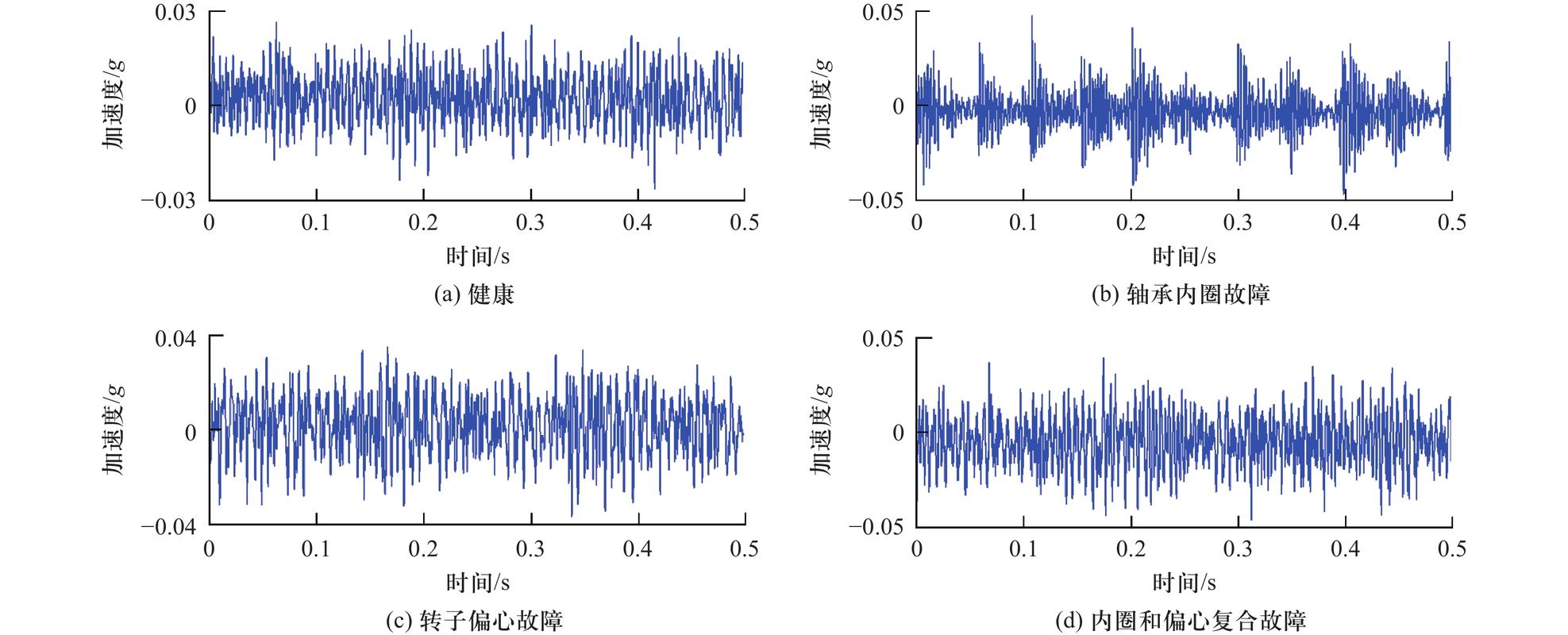
但有个例外:如果故障模式很清晰,且你有大量历史案例——比如某型号泵的轴承劣化全生命周期数据——那可以上卷积神经网络,直接吃原始振动波形,自动学特征。不过对大多数中小工厂,这绝对是奢望。
我自己最常用的套路:先用统计方法(如马氏距离)检测异常,再对异常段做频谱分析定位故障部件。算法不复杂,但有效。工业界要的是鲁棒,不是paper指标。
落地陷阱:数据质量与模型泛化
搞算法的常忽略一件事:标签噪声。设备报修记录经常写错,实际故障类型跟记录风马牛不相及。你训出来的模型,看似精度90%,一部署立马打折。怎么办?💡 得搭个数据清洗流水线,用规则+人工复核。另外,工况自适应是老大难。负载变化、转速波动导致特征分布漂移,模型就瞎了。迁移学习、域对抗网络有人研究,但工程化门槛太高。简单粗暴的办法:分工况建模,或者把工况参数作为特征丢进去。
问:振动传感器选加速度还是速度传感器?
答:看频段。加速度传感器高频响应好,适合轴承、齿轮早期故障;速度传感器低频稳定,多用于不平衡、不对中监测。现在大多用ICP加速度计,加个积分电路也能出速度。但注意安装方式——磁座、胶粘还是螺栓,对频响影响巨大。磁座省事但高频衰减严重,诊断轴承故障可能漏掉特征。
问:完全没有历史故障数据,怎么搞预测性维护?
答:很多人卡在这儿。其实可以用无监督方法。比如用自编码器学习正常状态的重构误差,误差突然变大就是异常。或者健康指标构建——振动总量趋势上升,加速包络值突增,这些不用故障标签也能抓到。再不行,就设简单阈值,统计分布偏离3-sigma报警。虽然粗,但总比没有强。
另一个现实问题:算法输出报警后,维修人员不信。你得把可解释性做透。用SHAP值解释哪个特征贡献大,或者直接给频谱对比图,标记报警频点与故障特征频率的吻合度。这样,老师傅才服气。
最后,别把预测性维护神化。它只是概率,不是算命。总有些随机失效预测不到。但通过数据累积和模型迭代,总能抓住大部分隐患。说到底,预测性维护算法的价值是让你从被动挨打变成主动出击。看着维修计划表上那些“未雨绸缪”的任务,心里踏实多了。
免责声明:文章内容来自互联网,本站仅作为分享,不对其真实性负责,如有侵权等情况,请与本站联系删除。
转载请注明出处:预测性维护算法实战:别等设备坏了再后悔 https://www.dachanpin.com/a/tg/55278.html