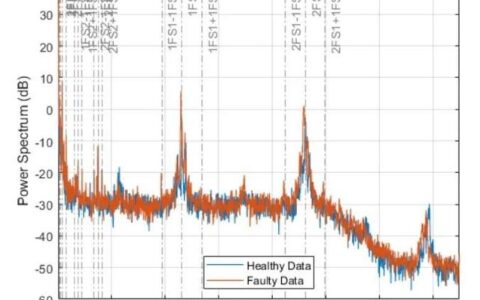
我上周去了一家做精密轴承的工厂,老板拉着我抱怨,说花了八十万上的“工业大数据平台”,跑了一年,车间主任每天还是靠手写报表。屏幕上那些曲线图没人看,我问一线操作工,他们反问我:“这玩意儿能告诉我后半夜刀头会不会断?”
说实话,当时我心里就咯噔一下。这又是一个典型的“为数据而数据”的翻车现场。
工业大数据的核心不是大,是“准”
很多人搞混了一个概念。工业大数据,重点不在数据量有多大,而在数据能不能揪出生产线上那根最脆弱的神经。比如一条汽车焊接线,每秒产生上万个点,但真正常用的,可能就是某个焊枪的电流波动、某个工位的节拍延迟。
问:工业大数据不就是把设备数据存起来分析吗?为什么那么多项目失败?
答:因为90%的工厂连数据源头都没理清楚。我见过太多所谓的“智能工厂”,底层PLC(可编程逻辑控制器)老旧得连网口都没有,全靠人工拿着U盘拷数据;传感器装了不少,但型号混杂,协议五花八门。数据上不来,上了云也是垃圾进、垃圾出。有一次,我们给一个化工厂做预测性维护,光是把反应釜的温度变送器校准统一,就折腾了三个月。老板中途差点放弃,觉得“你们这帮搞数据的怎么天天在跟螺丝较劲?”——但这就是现实,工业大数据的第一道鬼门关,永远是OT(运营技术)层的硬骨头。
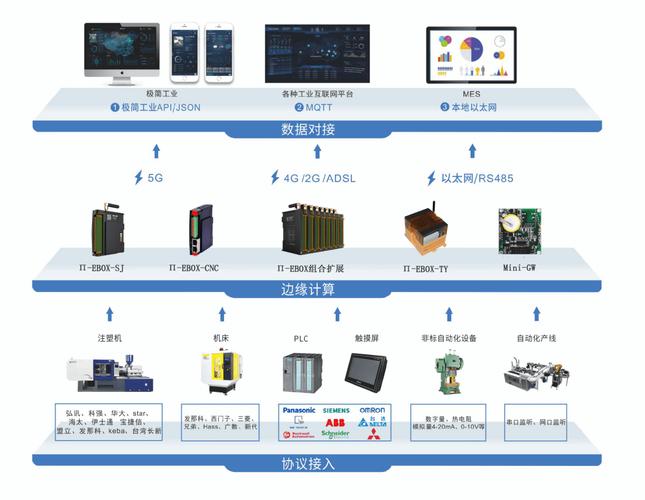
边缘计算:为什么不要把数据一股脑送上云端
现在又有一个潮流,叫“边缘计算”。听着挺唬人,其实说白了,就是在靠近设备的地方先把数据清洗、压缩,甚至直接做决策。不是所有数据都有资格享受宽带待遇。
去年我们给某风电集团做叶片振动监测,如果每秒把所有加速度传感器的原始波形传回数据中心,一天的存储费就能买半片叶片。疯了吧?后来在风机机舱里加了边缘网关,就地做FFT(快速傅里叶变换),只回传频率特征值。带宽省了,延迟也从秒级降到了毫秒级。那些坚持“全量上传”的同行,最后都死在了网费账单上。
问:边缘计算和工业大数据平台是什么关系?是不是有了边缘就不用平台了?
答:这是个好问题。边缘负责“快”和“省”,平台负责“全”和“深”。比如实时告警——轴承温度超过85℃立即停机——必须在边缘侧完成,不然等数据绕到云端再回来,轴可能都烧红了。但长期看,比如分析全年温升趋势与润滑脂寿命的关系,那就得靠平台把成千上万台风机的历史数据烩在一起,训练模型。两者不是替代,是互补。但很多厂商故意混淆,忽悠工厂买一堆盒子,最后数据孤岛更多了。小心❗
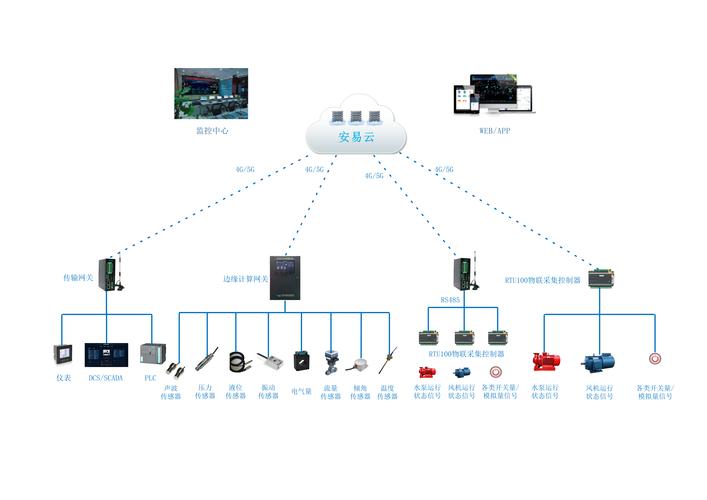
数据治理:谁才是数据的“主人”?
搞工业大数据,最容易被忽略的一点:数据所有权和治理。自动化部门说数据是他们的,IT部门说归他们管,结果两个部门老死不相往来。有一次我们帮一家家电巨头做良率分析,需要注塑机的工艺参数和质检MES数据关联。注塑数据在自动化部的中央控制器里,质检报告在IT部的SQL Server里。两边都不肯开放接口,最后是董事长拍桌子,才肯共享几个关键字段。这种政治问题,比技术本身难缠十倍。
所以现在我做咨询,第一件事不是画架构图,而是拉着各部门开会,定规矩:哪些数据必须实时共享,什么格式,谁对数据质量负责。没有这个共识,任何大数据项目都是空中楼阁。
问:小工厂没钱搞平台,怎么用好工业大数据?
答:先从Excel和免费时序数据库入手。没错,Excel。很多老师傅的经验其实都藏在交接班记录本里,把它们电子化,用Excel透视表分析故障频率,成本几乎为零。我见过一家做螺丝的作坊,老板自己学了Power BI,把机床的报警代码和停机时间可视化,三个月内故障响应速度提升了一倍。工业大数据不是非得高大上,能解决问题就行。💡
最后说一个反直觉的结论:未来几年,能活下来的工业大数据公司,不一定是IT最强的,但一定是最懂工艺的。因为数据本身没有灵魂,它得扎根在淬火、切削、注塑这些具体物理过程中,才能真正长出利润。
免责声明:文章内容来自互联网,本站仅作为分享,不对其真实性负责,如有侵权等情况,请与本站联系删除。
转载请注明出处:工业大数据踩坑指南:别急着上平台,先看看设备联网了没? https://www.dachanpin.com/a/tg/55336.html