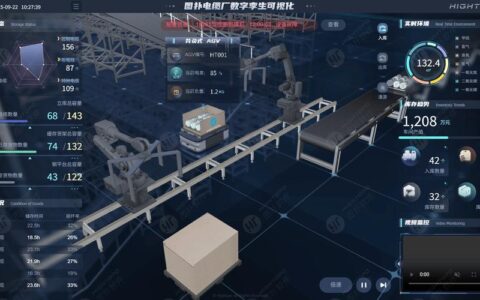
上周去一家做精密轴承的工厂,厂长拉我看他们的数据大屏。炫是真炫,各种曲线跳动,绿色数字往上窜。他特得意:“我们上了大数据平台,良品率肯定能提!” 我问了一句:数据从哪来的?他指了指角落里一台老掉牙的磨床,上面绑了个外挂传感器,线拖得跟蜘蛛网似的。得,我心里咯噔一下——这数据地基,怕是沙堆上盖楼。
数据采集,第一道坎就绊倒多少人
搞工业大数据,最头疼的不是算法,是数据采集。你兴冲冲买了套高级分析软件,结果发现车间里一半设备是“哑巴”。西门子、发那科的数控系统还好,有标准OPC UA接口。可那些用了二十年的国产铣床、冲床呢?连网口都没有。于是你开始搞改造,加传感器、装边缘网关,折腾一圈下来,成本比设备残值还高。老板脸都绿了。

而且采集频率也是个坑。我见过一个项目,振动传感器每毫秒采一次,一天就是几个G。数据哗哗地存进Hadoop,结果硬盘先撑不住了。实际上,你真有本事处理毫秒级数据吗?大多数预警场景,秒级足够。说白了,边缘计算不是摆设,得在源头做粗筛,别把垃圾数据往云端堆。可很多集成商为了卖设备,忽悠你上全套,唉……
问:工厂里很多老旧设备根本没有传感器,难道只能报废吗?
答:别急,报废是最后选项。可以先做可行性评估:看这些设备的关键参数是什么,比如主轴振动、温度、电流。然后选非侵入式传感器,像磁吸式的振动传感器、钳形电流互感器,不需要停机改造。再通过边缘计算盒子做数据预处理,用4G/5G传到平台。成本能控制在几千块一台。关键是你得清楚采集这些数据到底要解决什么问题,别为采而采。我见过一个厂,非要知道一台老冲床的冲压次数,加了个光电计数器就解决了,成本两百块。大数据不是数据大,是价值大。
数据质量,让你怀疑人生
好不容易数据上来了,打开一看,全是惊喜。同一个温度测点,早班记录是℃,中班变成℉,夜班干脆是字符串“正常”。ERP里的工时数据,有填8小时的,有填7.9的,还有填“加班”的——这怎么建模?别提什么数字孪生,连孪生他弟都不像。
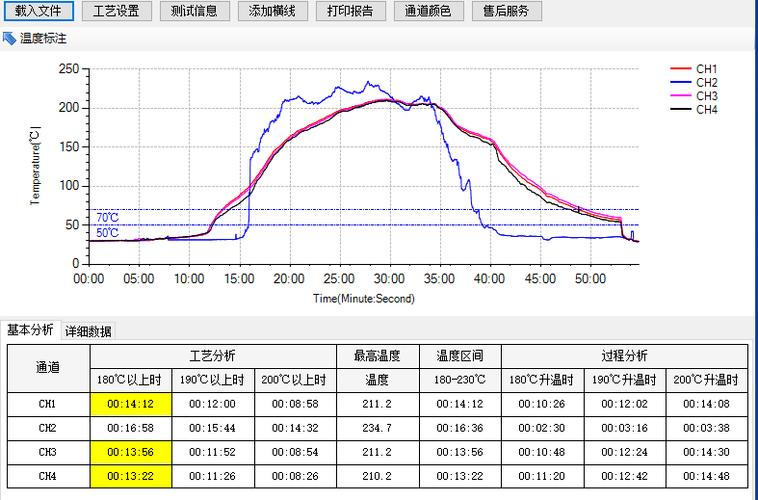
工业数据治理,脏活累活,费时费力。清洗规则写了一百多条,下个月产线换了种原材料,数据分布全变,规则又得重来。这时候你才明白,为什么那些AI公司 demo 做得天花乱坠,一到现场就哑火。不是算法不行,是数据太野。我特别想吐槽某些厂商,张嘴就是“人工智能赋能工业”,你倒是先帮我把数据弄干净啊!
而且工业数据有很强的时间相关性。一个阀门关闭动作,可能影响下游压力十分钟。你要是把时间戳对齐错了,特征提取全乱套。更别提那些由于NTP服务器宕机导致的时间漂移,几台设备时间差几秒,对于高速产线就是灾难。这些细节,不蹲车间根本不知道。
从数据到洞察,还得靠人

看着BI报表上漂亮的趋势图,厂长以为找到了金矿。可数据只会告诉你发生了什么,不会告诉你为什么。比如某设备振动值陡增,是轴承磨损?还是工装松动?还是今天换了个新手操作工?算法怀疑一切,给出75%置信度可能是轴承问题。你敢直接停机换轴承吗?一停就是半天产量,换下来发现轴承好好的,你背锅。
所以预测性维护真落地,得结合机理模型和专家经验。我曾在一条玻璃纤维产线上,把老师傅调窑炉参数的手感,硬是总结成几十条模糊规则,再融合到机器学习模型里,准确率才从60%提到85%。老师傅叼着烟说:“早这样嘛,鬼东西(指传感器)还不如我耳朵。” 我苦笑,心里认同一半。
问:都说预测性维护很神,实际落地最难的地方在哪?
答:难在故障样本太少。一条稳定运行的产线,一年可能就几次故障。你想训练个深度学习模型,样本量不够,正负样本失衡到离谱。然后你搞迁移学习,拿实验室数据补,结果现场工况一复杂,误报率飙升。操作工被误报搞烦了,直接关掉报警,系统就成了摆设。所以现在比较实用的方法是:先基于物理模型做故障模式库,再用数据驱动做残差监测。简单说,就是别指望AI替你扛所有,人机结合才是正道。另外,组织问题更大——预测出来故障,维修计划能跟上吗?备件库存够吗?很多MRO体系还是事后响应,你把预警提前两周,反而打乱他们节奏,人家不领情。
工业大数据喊了这么多年,真正吃透的企业没几家。不是技术不够,是生态太糙。从传感器安装、数据清洗、特征工程,到业务闭环,每一个环节都需要深耕。别再迷恋大数据万能论了,老老实实解决一个个具体问题。哪怕只把某台关键设备的OEE用数据算准了,也是真金白银。
最后说句扎心的:别让你的大数据平台,成为下一个昂贵的电子看板。就这样。
免责声明:文章内容来自互联网,本站仅作为分享,不对其真实性负责,如有侵权等情况,请与本站联系删除。
转载请注明出处:工业大数据:那些坑和惊喜,我都替你们蹚过了 https://www.dachanpin.com/a/tg/61004.html