1. Jsoup介绍官网文档:https://jsoup.orgJsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。2. Jsoup快速入门获取网页标题String url = “https://search.jd.com/Search?keyword=手机&wq=手机&page=1”; Document document = Jsoup.connect(url).get(); String title = document.select(“title”).text(); System.out.println(title);运行效果:手机 – 商品搜索 – 京东3. 网站数据分析3.1 分析网站的访问地址以京东商城为例,商品分页列表的url地址,需要带如下几个参数,因此,在发送http请求时,需要携带正确的参数。URL:https://search.jd.com/Search?keyword=手机&wq=手机&page=13.2 分析网站的页面结构通过浏览器的开发者工具,可以分析出页面中我们需要的html结构。 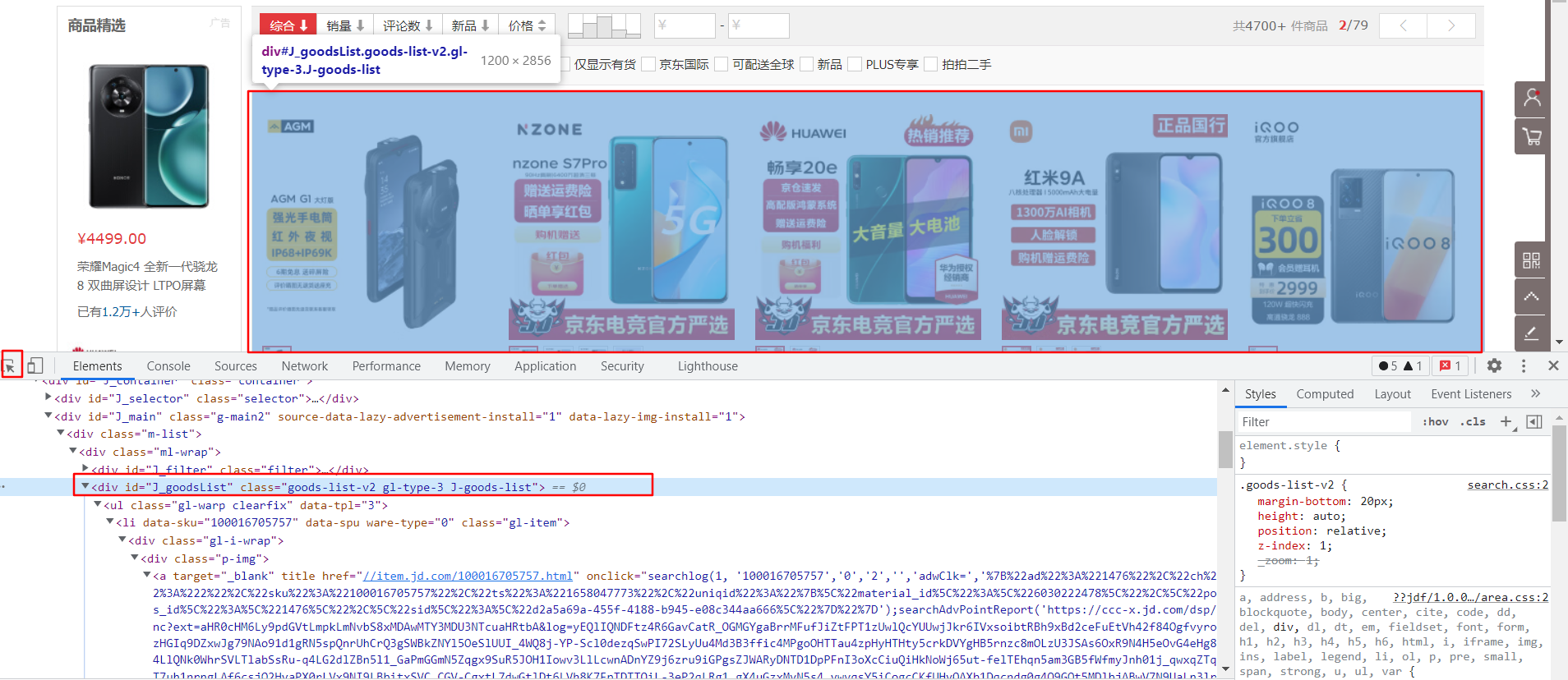 可以看出,我们需要的商品数据,封装在一个id=J_goodsList的div标签中,我们可以方便的通过DOM解析出这块数据。4. 实战实现过程获取第1页的商品基本数据public static void main(String[] args) throws Exception { //第1页地址 String url = “https://search.jd.com/Search?keyword=手机&wq=手机&page=1”; //发送http请求 Document document = Jsoup.connect(url).get(); //在id=J_goodsList的div下,获取所有带有data-sku属性的li标签 Elements lis = document.select(“div[id=J_goodsList] li[data-sku]”); lis.forEach( li -> { //获取商品sku String sku = li.attr(“data-sku”); //获取商品name String name = li.select(“div[class=p-name p-name-type-2] a em”).text(); //获取商品图片地址 String img = li.select(“div[class=p-img] a img[data-lazy-img]”).attr(“data-lazy-img”); System.out.println(String.format(“%s, %s, %s”, sku, name, img)); } ); }效果预览
可以看出,我们需要的商品数据,封装在一个id=J_goodsList的div标签中,我们可以方便的通过DOM解析出这块数据。4. 实战实现过程获取第1页的商品基本数据public static void main(String[] args) throws Exception { //第1页地址 String url = “https://search.jd.com/Search?keyword=手机&wq=手机&page=1”; //发送http请求 Document document = Jsoup.connect(url).get(); //在id=J_goodsList的div下,获取所有带有data-sku属性的li标签 Elements lis = document.select(“div[id=J_goodsList] li[data-sku]”); lis.forEach( li -> { //获取商品sku String sku = li.attr(“data-sku”); //获取商品name String name = li.select(“div[class=p-name p-name-type-2] a em”).text(); //获取商品图片地址 String img = li.select(“div[class=p-img] a img[data-lazy-img]”).attr(“data-lazy-img”); System.out.println(String.format(“%s, %s, %s”, sku, name, img)); } ); }效果预览  改造为分页获取public static void main(String[] args) throws Exception { //第N页地址 String url = “https://search.jd.com/Search?keyword=手机&wq=手机&page=” + i; //发送http请求 Document document = Jsoup.connect(url).get(); //在id=J_goodsList的div下,获取所有带有data-sku属性的li标签 Elements lis = document.select(“div[id=J_goodsList] li[data-sku]”); lis.forEach( li -> { //获取商品sku String sku = li.attr(“data-sku”); //获取商品name String name = li.select(“div[class=p-name p-name-type-2] a em”).text(); //获取商品图片地址 String img = li.select(“div[class=p-img] a img[data-lazy-img]”).attr(“data-lazy-img”); System.out.println(String.format(“%s, %s, %s”, sku, name, img)); } ); }
改造为分页获取public static void main(String[] args) throws Exception { //第N页地址 String url = “https://search.jd.com/Search?keyword=手机&wq=手机&page=” + i; //发送http请求 Document document = Jsoup.connect(url).get(); //在id=J_goodsList的div下,获取所有带有data-sku属性的li标签 Elements lis = document.select(“div[id=J_goodsList] li[data-sku]”); lis.forEach( li -> { //获取商品sku String sku = li.attr(“data-sku”); //获取商品name String name = li.select(“div[class=p-name p-name-type-2] a em”).text(); //获取商品图片地址 String img = li.select(“div[class=p-img] a img[data-lazy-img]”).attr(“data-lazy-img”); System.out.println(String.format(“%s, %s, %s”, sku, name, img)); } ); }
免责声明:文章内容来自互联网,本站仅作为分享,不对其真实性负责,如有侵权等情况,请与本站联系删除。
转载请注明出处:如何使用JAVA爬取网站数据? https://www.dachanpin.com/a/cyfx/11691.html