上周去一家工厂,设备经理老张拉着我吐槽:“这套压缩机上个月刚检修过,结果昨天突然趴窝了——产线停摆8小时,你说气不气!” 他猛嘬一口烟,“RUL这事儿,真特么玄学。”
我没忍住笑。确实,这几年大家都在谈剩余使用寿命(RUL),好像只要数据够、模型牛,就能掐指一算设备啥时候嗝屁。可现实呢? 打脸的时刻太多了。
✅ 什么是RUL?先别急着建模
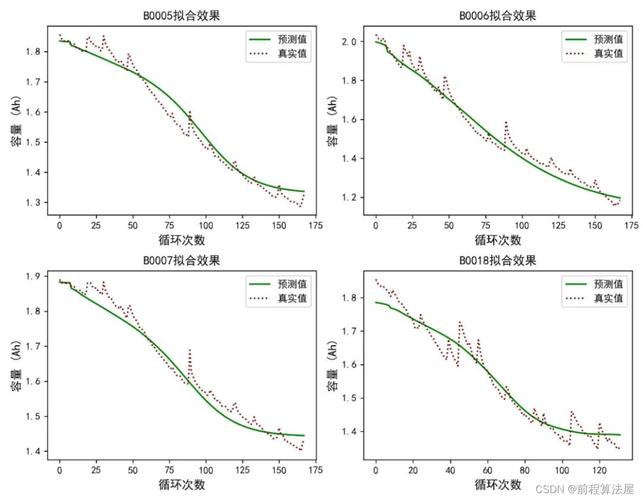
简单说,RUL就是设备从当前时刻到失效还能运行的时间。比如轴承已经转了8000小时,设计寿命10000小时,直觉告诉你还剩2000小时——但这几乎从来不成立。 环境、负载、润滑……每个变量都在悄悄更改这个数字。 更扎心的是,很多工厂连准确的历史故障记录都没有,数据脏得令人发指。
但工业人就是这么倔。我们还是想尽办法去猜。早期用物理模型,后来用统计,现在用机器学习。 可是—— 唉,说多了都是泪。
💡 物理模型到数据驱动:一场没完没了的博弈
十年前我做项目时,大家都信奉Paris定律那种物理退化模型。确实美,有解析解,可解释性满分。但一遇到复杂系统,比如航空发动机,参数多到爆炸,你根本建不准。 于是数据驱动方法来了。 神经网络、随机森林、LSTM……一股脑往上堆。 结果呢? 漂亮是漂亮,但出了实验室就翻车。 变工况、噪声、数据不平衡,模型直接懵圈。
有一次,我们给风电齿轮箱做RUL预测,训练时RMSE美得不行。上线后,第一个月还行,第二个月误差飙升——因为季节变化导致油温漂移,训练集里压根没这模式。 现场工程师冷笑:“就这?”

现在大家渐渐清醒了:混合模型也许更靠谱。 物理引导的数据驱动,或者叫灰箱模型,至少给网络塞点约束,别让它瞎猜。 不过说实话,门槛还是高。中小厂根本玩不起。
❗ 预测性维护不是买软件就完事儿
很多老板觉得,上一套预测性维护系统,RUL就自动出来,然后一切搞定。太天真了。 我见过最离谱的案例:某厂花几百万上系统,结果振动传感器装错位置,采集的数据全是对着空气的谐波。 没人发现,直到轴承烧了才反应过来。
问:RUL预测到底需要什么基础条件?
答: 第一,高质量的历史故障数据,至少包含退化曲线的几个典型完整周期;第二,特征工程要懂机理,不是随便扔几十个统计量就行的;第三,运维流程得跟上,预测结果没人看等于白搭。 缺一条,效果就打折。 很多厂连第一点都做不到,故障记录全是人为描述的笔记——“有点响”“温度偏高”,这种怎么用?
问:那现在有没有比较落地的RUL方案?
答: 有的。 一些工业互联网平台开始提供半定制化的PHM模块。 比如在泵群上,用基于相似性(相似工况下历史退化模式匹配)的方法,不需要海量故障样本,但要求有足够的运行历史。 还有用迁移学习的,让模型在新设备上少样本也能用。 但注意,这些都不是开箱即用,需要懂工艺的人深度参与。
还有个绕不开的痛点——剩余使用寿命的预测不确定性。 你给一个确定值,比如“还能跑300小时”,经理就敢压到315小时再停机。 结果第310小时崩了,谁背锅? 所以现在更倡导输出概率分布和置信区间,加上维护时机推荐。 但这又带来新的解释难题。
最新实践:数字孪生与边缘计算带来的曙光
今年在汉诺威展会上,我看到几个真正让我兴奋的案例。 一家德国公司把数字孪生和RUL结合,实时同步设备状态,用虚拟传感器补偿缺失测点。 他们的风机叶片RUL预测,竟然把误报率降低了70%! 而且模型在边缘端就地推理,数据不用上传云端,延迟和安全性的矛盾终于好了一丝。
不过—— 我说不过,成本还是高。 中小企业根本养不起这样一支跨界团队。 但趋势是好的,模块化、低代码平台的推进会让RUL民主化一些。
我自己最近在尝试用自动机器学习(AutoML)简化特征选择过程。 老实讲,效果不稳定,有时能惊喜地发现隐藏特征,有时跑出来的模型就是个黑箱,连我自己都不信。 但至少省了不少头发,对吧?
最后扯一句掏心窝的话:RUL永远不是纯技术问题。 它是管理、数据、机理、人机协同的混合体。 下次有人跟你吹嘘AI能精确预测寿命,你可以笑笑,然后问他:“你的训练集里,有去年夏天那场暴雨导致湿度骤增的工况吗?”
大概率,他会愣住。 而你,已经看清了这条路上最大的坑。
免责声明:文章内容来自互联网,本站仅作为分享,不对其真实性负责,如有侵权等情况,请与本站联系删除。
转载请注明出处:预测设备还能撑多久?剩余使用寿命(RUL)的坑与光 https://www.dachanpin.com/a/tg/59433.html