干了十五年自动化,说实话,我最怕的不是设备停机——是老板突然对着一堆报表问我:’这些数据到底能变成多少钱?’ 你能理解那种感觉吧,明明采集系统每分钟都在往里灌数据,结果呢?成了没人看得懂的’数字废料’。
但去年在宁波一家注塑机厂看到的东西,真的让我眼前一亮。他们居然把过去两年半的所有工艺参数——温度、压力、螺杆转速,从200毫秒一个点的原始流数据里硬生生淘出了规律。不是那种’大概可能’的关联,是精准到能提前17分钟预警模具磨损的模式。💡 这就是工业大数据的正确打开方式。
数据采集,99%的人都踩过同一个坑
一提到工业大数据,很多人立刻想到 Hadoop、Spark 那一套,好像只要堆上集群就万事大吉。可实际情况呢?工控机里跑的还是 Windows 2000,PLC 协议封闭得连西门子自己都说不清版本。 有一次我们去给一家钢铁厂做数据接入,光是让轧机里的数据流出来,就花了整整三周——因为找不到能兼容 Profibus-DP 和 EtherNet/IP 的中间件。😤
现在稍微好点儿,OPC UA 慢慢成了事实标准,但老旧设备改造依然是噩梦。我的建议很直接:别指望统一所有接口。 用一个轻量级边缘网关做协议转换,把数据汇聚成 MQTT 流推上去,成本低且可靠。对了,边缘计算还有一个被严重低估的好处——它能就地做数据清洗,砍掉90%的无用振动噪声,省下来的带宽和存储看着不起眼,算起来吓死人。
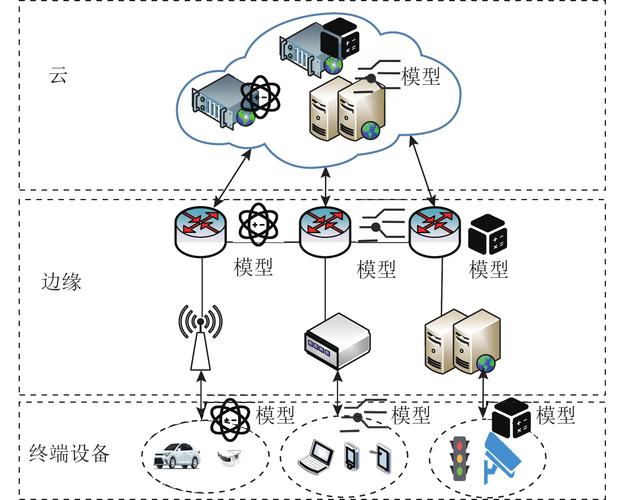
然后呢?数据进来了,存哪儿?时序数据库是必需品,但很多人忽略了上下文数据——比如同一时刻环境温湿度、操作员工号、原料批次。这些散落在 MES、ERP 里的结构化数据如果不跟时序数据对齐,你做的任何分析都是残缺的。这就是为什么我们后来强制要求所有数据打上统一的时间戳和资产标签,不然根本没法用。
从’看见’到’预见’,中间隔着一座桥
聊到分析,我又爱又恨。爱的是机器学习模型确实牛——我们用 LSTM 对风机轴承的退化趋势建模,把突发的非计划停机减少了 60%。恨的是,模型落地总是一波三折。实验室里准确率 95%,到现场直接掉到 70% 以下,因为训练集里根本没出现过实际工况中那种忽大忽小的负载波动。❗所以现在我带团队,铁律之一就是:至少拿三个月横跨不同季节、不同班次的数据做验证,少一天都不行。
问:老板关心投资回报,怎么把预测性维护的价值讲清楚?
答:别谈技术,谈钱。我通常算两笔账:一笔是直接损失——一次非计划停机导致的生产线停滞、紧急采购备件的溢价;另一笔是隐性成本——过度维护换下来的零件其实还有 30% 寿命、库存资金积压。用真实历史数据拉 Excel 曲线给他看,比一百页 PPT 都有说服力。不过话说回来,如果连基础的数据治理都没做好,这些数字全是空中楼阁。
问:数字孪生听起来特别高大上,实际落地到底卡在哪儿?
答:卡在’实时’二字。传统仿真模型是离线的,而数字孪生要求秒级甚至毫秒级的双向数据同步。这意味着你的网络、数据库、模型计算引擎必须全部配合上。我们做过一个注塑机数字孪生项目,光是让模型状态跟随真实机台刷新,就折腾了两个月——因为模温机传递函数随模具老化会漂移。最后用了在线参数辨识算法才搞定。💡如果你现在想上手,建议从单个关键设备开始,别一上来就搞全厂级。
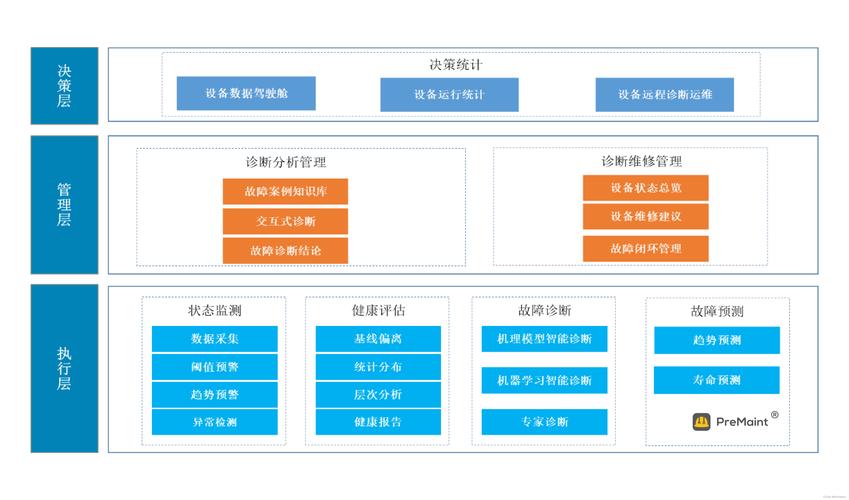
把数据变成决策,这才是终极难题

去年拜访一家新能源电池工厂,CIO 给我看了他们的’智慧大屏’——酷炫的 3D 地图、跳动的产能数字,所有人经过都得抬头看两眼。但我多问了一句:‘这个屏上的数据,引发过几次现场行动?’ 他愣了一下,说好像没有。
这就是典型的’数据虚荣’。工业大数据的终点不是在屏幕上美丽,而是驱动一线操作工、班组长和维修工程师做出不一样的动作。我们试过一个笨办法:把分析结果直接推送到工位上的 Andon 屏,甚至用短信告诉机修工’3号压机曲轴油压异常,请带17mm扳手’。😅 虽然土,但效果立竿见影。
最后想说一个容易被忽视的点:工业知识的数字化。很多老师傅能听声音判断齿轮啮合是否正常,这种隐性知识如果不用数据固化下来,人走了经验就没了。我们现在用声学传感器采集高频振动,配合老师傅的标记,训练出一个微安级故障识别模型——上个月真的提前捕获了一次罕见的轴承保持架裂纹,避免了几十万的损失。那一刻,整个团队都觉得值了。
工业大数据这条路,没有捷径。数据基础、分析工具、组织流程,缺任何一个环节都会让投资打水漂。但它一旦跑通,释放的价值远超任何单点自动化升级。我至今记得宁波那家注塑机厂老板的话:’以前我们是救火队,现在终于能当天气预报员了。’ 这大概就是工业大数据的魅力所在。
免责声明:文章内容来自互联网,本站仅作为分享,不对其真实性负责,如有侵权等情况,请与本站联系删除。
转载请注明出处:工业大数据:从数据沼泽到价值金矿的真实路径 https://www.dachanpin.com/a/tg/60477.html