什么是urllib?
urllib库是Python内置的HTTP请求库,它可以看做是处理URL的组件集合。urllib库包含了四大模块,具体如下:
urllib.request:请求模块urllib.error:异常处理模块urllib.parse:URL解析模块urllib.robotparser:robots.txt解析模块快速使用urllib爬取网页爬取网页,其实就是通过URL获取网页信息,这段网页信息的实质就是一段附加了JS和CSS的HTML代码。如果把网页比作是一个人,那么HTML就是它的骨架,JS是它的肌肉,CSS是它的衣服。由此看来,网页最重要的数据部分是存在于HTML中的。
urllib库的使用比较简单,接下来,我们使用urllib快速爬取一个网页,具体代码如下:
importurllib.request #调用urllib.request库的urlopen方法,并传入一个url response=urllib.request.urlopen(http://www.baidu.com) #使用read方法读取获取到的网页内容 html=response.read().decode(UTF-8) #打印网页内容 print(html)上述代码就是一个简单的爬取网页案例,爬取的网页结果如图4-1所示。
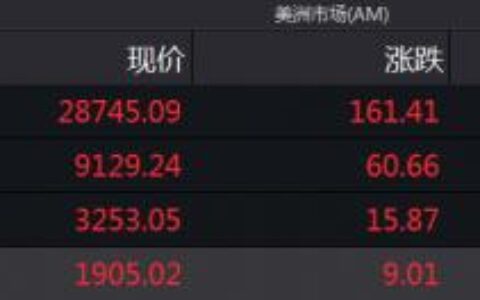
获取的网页源码
实际上,如果我们在浏览器上打开百度首页,右键选择“查看源代码”,你会发现,跟我们刚才打印出来的是一模一样。也就是说,上述案例仅仅用了几行代码,就已经帮我们把百度首页的全部代码下载下来了。
多学一招:Python2使用的是urllib2库Python2中使用的是urllib2库来下载网页,该库的用法如下所示:
importurllib2 response=urllib2.urlopen(http://www.baidu.com)Python3出现后,之前Python2中的urllib2库被移到了urllib.request模块中,之前urllib2中很多函数的路径也发生了变化,希望大家在使用的时候多加注意。
免责声明:文章内容来自互联网,本站仅作为分享,不对其真实性负责,如有侵权等情况,请与本站联系删除。
转载请注明出处:如何快速使用urllib爬取网页? https://www.dachanpin.com/a/cyfx/10893.html