那件事发生在去年秋天。我们在一家精密加工车间部署数字孪生,刚上线第三天,系统突然报警:主轴温度异常,预测将在2小时内失效。现场工程师看了一眼,骂了句“扯淡”——测温枪显示一切正常。但15分钟后,主轴真的崩了,刀具飞出来差点伤人。那一刻,整个车间安静得可怕。我盯着屏幕上那个还在旋转的虚拟主轴,心里既有后怕,也有一种诡异的兴奋:这玩意儿居然真能预见未来?不过后来我们才发现,那个准确的预测不过是瞎猫碰上死耗子——数据链路里有个延迟bug,让温度曲线正好歪打正着。这就是真实的数字孪生,远不是PPT里那么光鲜。
到底什么是数字孪生?别再拿3D模型糊弄人了
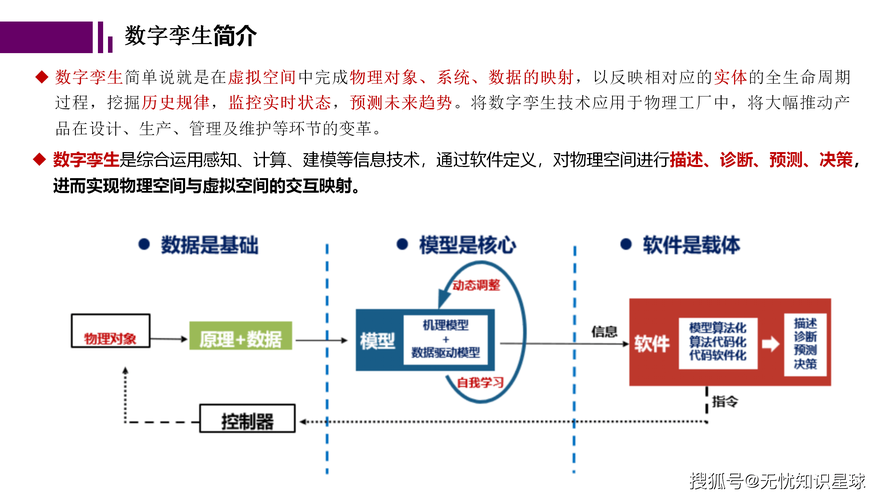
很多人以为给设备建个三维模型,接到大屏上动一动,就是数字孪生了。说实话,这想法让我想起当年CAD刚普及时,也有人觉得画个图就是数字化。数字孪生的核心在于实时数据驱动和双向交互。你得让物理世界的每一次振动、每一点温度变化,都在数字空间里同步映射;反过来,数字空间的分析结果要能控制物理设备。这不是demo,而是一套需要持续喂养数据的活系统。
打个比方,你家里装个摄像头看宠物,那只是视频监控。但如果摄像头能识别狗的情绪,自动调整喂食器,甚至预测它什么时候会拆家——那才是孪生的思路。不过工业场景更严苛,一个传感器数据丢失,可能就导致模型判断失误。我们早期就犯过这种错:用了某家的通用物联网平台,数据采集频率不稳定,结果孪生体的设备动作比实际慢了800毫秒,这在协同产线上简直是灾难。
问答:仿真和数字孪生到底啥关系?
问:我以前用过ANSYS做仿真,这和数字孪生不是一回事吗?为什么还要再搞一套?
答:好问题。仿真更像是拍一张高清照片,你输入一堆假设条件,计算出一个最优解。但数字孪生是拍电影——它要反映对象随时间变化的过程,而且这个电影还在实时更新剧本。比如,你用仿真优化了一个叶轮的流体设计,那是在设计阶段;可一旦这个叶轮装上机器运转,磨损、结垢、工况波动这些脏活累活,仿真模型就管不到了。数字孪生会持续接收来自真实叶轮的振动频谱、流量数据,不断修正自己的状态,然后告诉你:“根据当前磨损率,三个月后效率将下降5%,建议下周二早班换掉它。” 它能回答“现在怎样”“将来会发生什么”,而仿真更多是回答“如果……会怎样”。不过话说回来,仿真确实是孪生的基础之一,很多孪生体的内核就是降阶的仿真模型,再加上数据驱动算法。所以两者不是取代关系,而是融合关系。
搭建数字孪生,最难的其实是“接线”
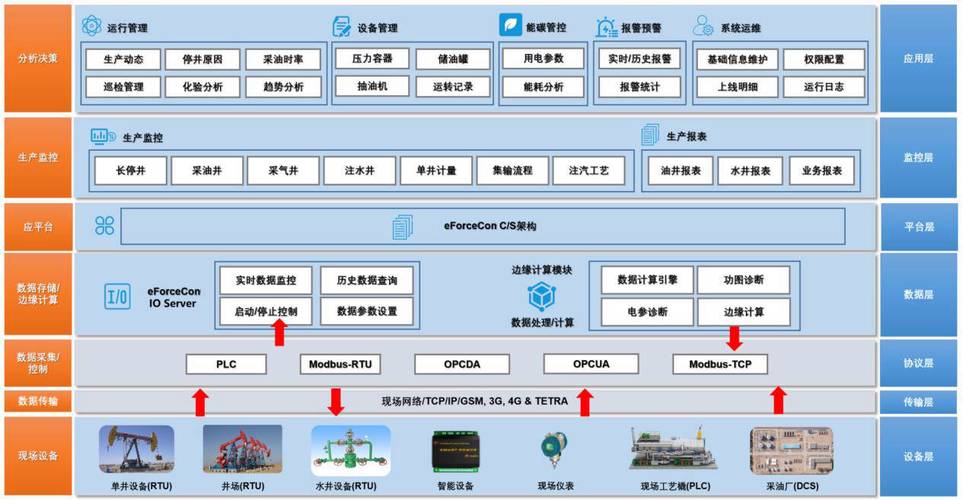
几个月前,我去一家注塑厂交流,他们IT部门给我看了一个炫酷的数字孪生界面,所有设备都闪着绿灯。我问数据源来自哪里?答:PLC直采,用的OPC UA。我打开一个隐藏的诊断面板,发现60%的测点其实是用历史平均值填充的,因为现场传感器根本不够。这事儿我见得太多了。很多工厂连最基本的数字基座都没搭好——老旧的继电器控制柜、五花八门的通讯协议、贴牌PLC的封闭生态……你想把数据抽出来?先准备好几十种驱动和中间件吧。
我们团队后来总结出一条血泪经验:做数字孪生,70%的工作是数据工程,30%才是建模和算法。这里说的数据工程,包括传感器选点、边缘节点部署、时间序列对齐、脏数据清洗,还有那该死的时钟同步。有一次,因为交换机时间服务器不准,整个车间的数据序列全部错位,孪生模型直接崩溃。那天晚上我盯着服务器日志,突然觉得这活儿真不是人干的。
不过一旦数据流打通,那种掌控感又很上瘾。就像打通了任督二脉,设备开始对你“说话”。我们曾给一台老旧的数控机床加装了三轴加速度传感器和油液颗粒计数器,然后训练了一个LSTM模型。三个月后,模型不仅能提前数小时预警刀具破损,还能根据切屑形状反推荐进给参数。操作工老张一开始死活不信,说这玩意就是骗经费的。直到有一天,屏幕上弹出一条建议:“降低0.02mm切深,振纹风险85%”。他半信半疑地调了参数,结果那批零件的表面粗糙度一下达标了。老张后来逢人就拍大腿:“那个电脑成精了!” 其实哪有什么成精,不过是数据喂够了。
问答:花几百万上数字孪生,值不值?

问:我们就是一家中小型零部件厂,利润很薄,数字孪生听起来太贵了,有没有性价比高一点的搞法?
答:完全理解。一说数字孪生,很多人就想到大屏、黑灯工厂、满墙的服务器,其实那都是面子工程。你完全可以从单台关键设备开始。比如,一台精密磨床,加装几个传感器成本不过几千块,再找个会用Python的数据分析师(或者外包),先把故障特征库跑起来。我们帮一家小厂这么做,就用树莓派采集主轴振动,上传到云端做FFT分析,半年避免了一起主轴抱死事故,省下的维修费就回本了。关键是你要明确孪生的目的:是为了减少非计划停机?还是优化工艺?或者追溯质量?目的不同,架构完全不同。别一上来就搞数字工厂,那是无底洞。先做设备级的“微孪生”,跑通了再扩展。记住,数据积累需要时间,所以早点开始,哪怕只是存下来数据,也比后来补课强。
那些被寄予厚望的自愈功能,走到哪一步了?
去年汉诺威工业展上,几乎所有大厂都在谈自主运行(Autonomous Operations),就是说数字孪生不仅能预测,还能自动调整参数,甚至自我修复。看起来很美好,但现场演示基本都是在理想环境下。我在一条实际产线测试过所谓的“闭环优化”,让孪生系统动态调整焊机的电流。结果第一天还好,第二天因为电网波动,模型误判为电弧不稳定,开始疯狂拉高电流,差点烧了变压器。吓得我们赶紧切回了手动。
所以,现在谈完全自愈还为时过早。但部分自愈已经可行,比如在稳态工况下,自适应PID参数的调整。这需要极高的模型置信度,而且必须设置严格的边界条件。我常跟团队说,你可以把车开得更聪明,但方向盘还得握在人手里。不过最近多智能体强化学习的进展很快,也许再过两年,我们真的能开始逐步放手。
哎,说起来,数字孪生现在的热度有点过火了。好多企业是被“灯塔工厂”的名头给忽悠进去的,最后花大价钱做了一套只能演示的系统。我建议,上任何数字孪生项目之前,先问自己三个问题:我的数据基础够吗?我的业务痛点匹配吗?我的人准备好了吗?
这行干得越久,我越觉得数字孪生本质上不是技术问题,而是组织变革。你得让设备部门、IT部门、工艺部门坐下来一起对骂几次,才能搞清楚到底要建什么。那些一上来就找外部团队全套打包的,最后系统必然吃灰。
深夜写到这里,车间线上的数据还在跳。数字孪生这条路,坑多,但光也不少。也许明年此时,我们那条预警失败的产线,已经能自我调整了?谁知道呢。干我们这行的,不就是在不确定里找确定么。
免责声明:文章内容来自互联网,本站仅作为分享,不对其真实性负责,如有侵权等情况,请与本站联系删除。
转载请注明出处:数字孪生:我亲手搭建的系统差点搞垮一条产线 https://www.dachanpin.com/a/tg/54781.html