设备还能撑多久?这个问题在工厂里简直像是悬在头顶的剑。说实话,没人愿意哪天突然停机,因为那意味着钱在哗啦啦地流走——维修、停产、交期延误,想想就头疼。然而,我们偏偏又没法直接看到机器内部的损耗。于是,‘剩余使用寿命(RUL)’这个概念,成了解锁预测性维护的钥匙。
RUL不是新词,但近几年它被讨论的频次高得离谱。为什么?因为传感器便宜了,数据多了,算法也猛了。过去我们靠师傅听声音、靠固定的保养周期,现在呢?试着用振动频谱、油液颗粒计数,甚至设备运行日志去推算一个精准的剩余寿命。不过,这条路远比想象的难走。
什么是剩余使用寿命(RUL)?——别和‘使用期限’搞混
很多人一上来就把RUL等同于设计寿命或保修期,那可差远了。设计寿命是理想环境下的理论值,而RUL是动态的、实时的、针对当前这台设备在当前工况下还能运行多久的预判。⚠️ 举个例子:同一型号的泵,一台输送清水,一台输送含颗粒的浆液,三五年后,它们的RUL能一样吗?显然不。
说白了,RUL = 失效时刻 – 当前时刻。失效时刻又是什么?根据ISO 13381-1,它可以是功能性失效(比如流量骤降)、性能衰减到阈值(如功率上升10%),甚至安全风险不可接受的那个点。这就引出了一个核心难题:失效定义不同,RUL的算法就完全不一样。哎,又是一个坑。
正因为这样,做RUL预测,第一步不是建模,而是拉着工艺、维修、设备厂商一起,把‘什么叫坏了’这件事吵清楚。这过程,没参与过的人真体会不到那种纠结……
预测RUL的主流方法:从经验公式到深度学习
提到方法,不少论文会直接扔出三种:基于物理模型、数据驱动、以及混合方法。但我得坦白说,在真正的工厂里,纯物理模型很难搞。因为你需要准确的失效机理——疲劳裂纹扩展、磨损系数、腐蚀速率……这些参数要么来自实验室,要么依赖材料手册。现实中的设备,往往装在一个沾满油污、振动紊乱的环境里,手册数据?呵呵。
所以数据驱动的方法突然就香了。✅ 特别是那类能处理多维时序数据的算法:随机森林、梯度提升机、再到长短时记忆网络(LSTM)。它们不管物理方程,只从历史运行数据里寻找模式:当轴承的某个频段振动幅值慢慢爬升,当温度梯度出现异常抖动,当电流信号的峭度指标突变……这些征兆再往前一步,不就是失效吗?算法捕捉的就是这个‘往前一步’的规律。
但是,数据驱动也有死穴:需要大量、有标记的退化数据。而大部分工厂根本没那么多失效样本——谁会故意让一台设备跑到报废来采集数据?所以迁移学习、生成对抗网络(GAN)开始被用来做数据增强,或者从相似设备的退化过程中‘借’知识。听起来很美,但实际部署时,模型漂移、工况变化会让预测结果像过山车。有一次我们把实验室准确率99%的模型放到一条实际产线上,RUL预测误差超过200%,真是打脸。
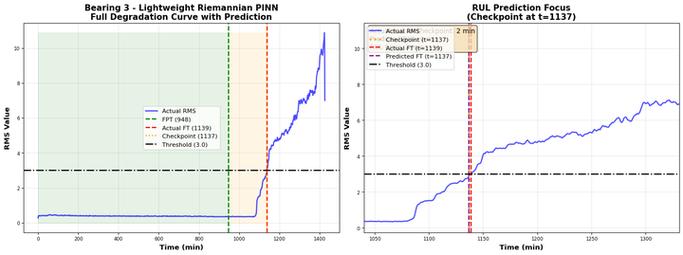
落地RUL预测时常被忽视的三个关键问题
聊完方法,必须说说那些听起来不那么酷,却能决定项目死活的问题。💡
1. 数据质量与时间戳对齐。 设备数据可能来自PLC、SCADA、振动监测系统、离线巡检仪……时间戳错位、采样频率不一、数据断层,是家常便饭。我们曾花几个月清洗数据,结果发现传感器时钟每天慢两秒。你说这RUL怎么算?差之毫厘,谬以千里。
2. 预测不确定性的表达。 给出一个确定的天数,比如‘剩余寿命87天’,并不诚实。真正的工业环境需要概率分布。RUL应输出一个区间,比如‘以90%置信度,剩余寿命在60-120天之间’。这样维修决策才能和风险挂钩。忽视不确定性,等于把决策者往火坑里推。
3. 人与模型的协作。 很多人幻想RUL系统能完全替代人,但现阶段,靠谱的用法是让模型给出预警,再由经验丰富的工程师二次判断。模型会忽略一些异常事件,比如突然的异物敲击,而人会立刻警觉。这种互补关系如果处理不好,技术再先进也落不了地。
常见问题:读完你的困惑,我直接回答了
问:小工厂没有数据科学家,怎么搞RUL?是不是只能等死?
答:别慌,不是一定要上深度学习。许多设备商已经提供内置的RUL计算模块,比如基于规则的方法——监测值超过阈值就触发警报,然后用线性退化趋势估算剩余时间。虽然简单,但实用。也可以从最容易采集的参数入手,比如电机电流。用统计过程控制(SPC)的思想,当趋势显著偏离基线,就该引起注意。先从小处做起,数据积累多了再升级模型。
问:RUL预测值忽高忽低,操作工完全不信任何办?
答:这太常见了!除了改进模型鲁棒性,更要修炼‘内功’:做好数据平滑、剔除离群值、引入指数加权移动平均(EWMA)。同时,在呈现给操作工时,不要只扔一个数字,加上趋势图、历史预测置信区间,让他们看到过程的稳定性。另外,把RUL的预测逻辑和限制透明化,坦诚沟通,信任是慢慢建立的。

问:现有的设备已经装了CMS(状态监测系统),为什么还需要独立的RUL分析?
答:CMS通常只做报警和简单的趋势分析,而RUL预测需要融合更多的上下文——维修记录、工况变化、甚至备件库存信息。单独分析能更灵活地定制退化模型,并且把结果直接推送给维修排程系统。好的RUL系统应与CMS分工协作,而不是替代关系。
走到这里,你可能会发现:RUL并不是一个纯技术问题,它是组织流程、数据工程、算法和领域知识的混合体。这几年,随着工业物联网平台和边缘计算的发展,RUL的实时计算越来越可行,但真正的挑战还是那些老问题——数据基础、人员认知、业务闭环。我们离‘任何时候都能准确知道设备何时故障’还有距离,但每往前跨一步,带来的收益都是实打实的。
未来,RUL可能会和数字孪生深度融合,通过实时仿真不断修正预测。也可能出现更轻量级的自监督学习,减少对标签数据的依赖。不管怎样,对于设备密集型企业,RUL这张牌如果打好,很可能成为竞争力的一部分。如果你也在尝试,不妨从定义失效、搭建数据管道开始,迈出第一步,后面的路再难,也值得。
免责声明:文章内容来自互联网,本站仅作为分享,不对其真实性负责,如有侵权等情况,请与本站联系删除。
转载请注明出处:工业设备寿命预测的关键:剩余使用寿命(RUL)深度解析 https://www.dachanpin.com/a/tg/56295.html