上周去浙江一家汽车零部件厂,碰上他们一条产线半夜宕机——主轴断了。值班工程师调了三个月的历史数据,最后发现早在两周前振动频谱就出现异常,可 DCS 系统根本没报警。他苦笑:‘数据我们存了,但没能力实时分析,等于白存。’ 这话刺耳,却道出许多工厂的痛——数据海量,决策却是滞后的。
工业自动化走到今天,传感器价格跳水,我们给每台机组装上一堆‘感知神经’不难。难的是怎么让这些神经瞬间反应,而不是等数据绕到云端再‘马后炮’。预测性维护这个老概念,正被边缘计算重新点燃。😂 说真的,以前一提边缘计算,总觉得是厂商造的词,玩噱头。但去年跟着几个项目落地,我得承认:在实时性就是生命的产线上,把算力下沉,可能是近几年最务实的技术转身。
从被动维修到主动预测,距离不是想法是时延
传统维护无非两种——要么坏了修(事后),要么按固定周期换(预防)。前者代价太大:一根轧辊故障可能毁掉整班产量;后者浪费惊人,很多零件还能用很久就被换下。预测性维护的迷人在哪里?它像给设备做动态心电图,通过振动、温度、油液颗粒等参数,提前告诉你‘这家伙下周二可能出问题’。
但过去的预测性维护方案,大多依赖中央服务器或云平台。现场采完数据,打包上传,跑模型,再返回指令。问题出在那几百毫秒甚至几秒的来回时延。对高速冲床、机器人焊接工位来说,这几秒可能已造成焊接偏移或模具损伤。更别提网络抖动——工厂环境电磁干扰严重,断流时有发生。❗ 把模型直接部署在设备旁的边缘网关里,逻辑判断在本地完成,只把处理后的特征数据和告警上传,这种‘就地裁决’的思路,一下把响应压到毫秒级。

记得在常州一家齿轮厂,他们给滚齿机加装边缘计算节点后,主轴不对中趋势的捕捉提前了至少40分钟。以前等云端跑完模型,刀具都快崩了。现在本地振动频谱分析结合电流信号,一秒内就能判断是否要降速或停机。车间主任老周用本地话说:‘这玩意儿比巡检工灵敏多了,而且不偷懒。’——是句大实话。
不过嘛,这事也没那么神。算法才是灵魂。硬件搭起来容易,懂工业机理又懂数据建模的人才极度稀缺。很多集成商装完传感器、连上边缘盒子,最后发现报警逻辑还是简单的阈值超限,根本不是真正的预测。🚫 这周我就被一家号称‘AI预测维护’的供应商气笑了,他们把‘温度超过90度就发短信’叫做AI模型。拜托,稍微加点频谱包络分析和特征频率提取很难吗?
边缘计算凭什么成为工业自动化的宠儿
如果只是时延问题,边缘计算不会火这么快。它的价值是多维的。首当其冲是数据隐私和合规:有些军工、核电企业根本不允许数据出园区,边缘计算让模型在本地迭代,敏感参数不用上云。其次是带宽成本:一台数控机床每秒产生几万条数据,全上传?网络费用和存储成本很高。边缘层做数据清洗、特征浓缩,压缩比轻松做到1:1000。再说,很多老旧设备通信协议奇葩,边缘网关充当协议转换的万能胶,把 Modbus、Profinet、EtherCAT 揉到一起。
但边缘计算真正撬动工业自动化格局的,是它与时间敏感网络(TSN)、5G 专网的深度融合。去年汉诺威展上,我看到一套 demo:多个机械臂通过 TSN + 边缘服务器实现微秒级协同,同时把关节扭矩、速度传给边缘预测模型,一旦某个轴力矩曲线异变,直接触发容错路径规划。✅ 这种确定性低时延的控制,纯靠云端根本做不到。
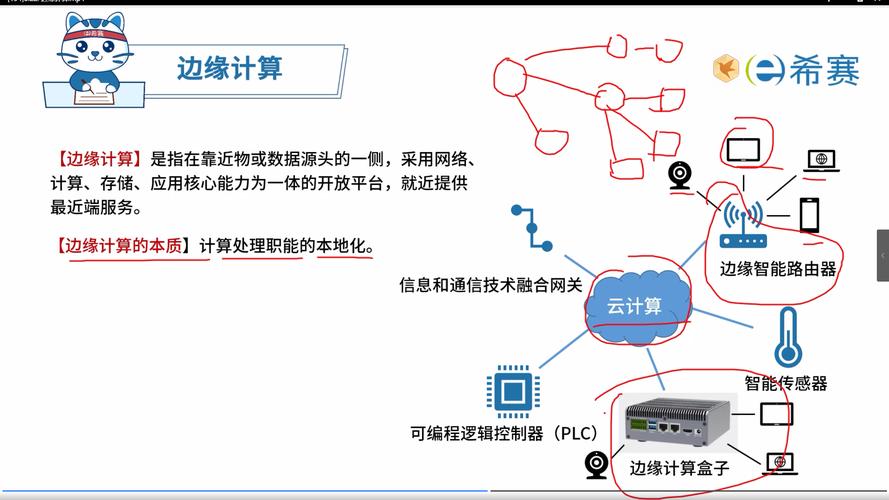
当然,挑战也赤裸裸。工业现场环境恶劣——油污、震动、高温,边缘硬件必须宽温宽压,很多 X86 工控机根本撑不住。于是出现了大量 ARM 架构的无风扇边缘盒子,功耗低,但算力相对有限,跑复杂模型吃力。这就需要软件层面的优化,比如模型量化、剪枝。💡 说实话,选型时千万别迷信算力参数,一定要做现场 POC(概念验证),让设备在真实电磁噪声下连续跑一周看看有无死机。
问:边缘计算和云计算到底差在哪?在预测性维护里为什么边缘更靠谱?
答:简单说,边缘算力部署在靠近设备的地方,通常在工厂内部;云计算则是集中式的远程数据中心。关键差异不是技术架构,而是物理距离带来的时延和可靠性。预测性维护需要毫秒级响应,比如高速动平衡机,云端传输加上模型推理可能超过 2 秒,轴承已经烧了。边缘端可以做到低于 10 毫秒。另外,工厂的网络时常不稳定,边缘能断网运行,本地缓存数据,网络恢复再同步——这种离线自治能力至关重要。
问:部署边缘预测性维护系统成本高吗?中小企业玩得起吗?
答:这是很多人担心的。目前一套基础方案(含传感器、边缘网关、基础软件)大约几万元,对关键设备不算贵。但要真正见效需要诊断专家定制模型,这部分服务费才是大头。中小企业可以从单点试点入手,比如先做空压机或注塑机的预测维护,硬件成本可控,模型也可用一些开源的异常检测框架训练。不过提醒一句:千万别指望采购一套标准产品就万事大吉,没有本地工艺知识和历史故障数据的喂养,模型就是废铁。我们曾为一台老旧轧机建模,花了三个月分析故障记录,最终才把剩余寿命预测精度提到 85% 以上。这个过程无法省钱,但确实能换来真金白银的减少非计划停机。
实战中的坑与经验
说到底,预测性维护怕的是‘为预测而预测’。我见过一家家电钣金车间,在冲床上装了全套边缘预测系统,但生产线节拍根本不允许停机维护,告警发出也只能干看着。这种场景还不如做个简单点检提醒。🎯 所以,价值点一定要对准生产瓶颈——那些停机损失巨大或安全风险高的设备。比如化工反应釜搅拌器、风电齿轮箱、矿用提升机——一旦非计划停,半天损失几十万。
另一个坑是数据标记。预测模型需要大量故障工况数据,但现实是,多数工厂设备保护得很好,故障样本稀少。这就得用迁移学习、生成对抗网络来弥补,甚至故意在实验中让设备失效(破坏性测试)来获取信号。这些操作需要工厂一把手拍板,因为涉及风险。但若没有高质量标签数据,算法在真故障面前可能沉默,这是最危险的。
最后想说,边缘计算不是银弹,但它正在把工业自动化的决策能力从中心化的‘大脑’推向分布的‘神经节’。这符合自然界的逻辑——低级反射不需要经过大脑,才能足够快。当预测性维护真正部署到边缘,我们终于可以跟那种‘故障事后追溯会’说再见了。不过……技术演进总是伴随着夸大其词的营销,擦亮眼睛吧,别被那些满嘴术语的销售带偏了。😉
免责声明:文章内容来自互联网,本站仅作为分享,不对其真实性负责,如有侵权等情况,请与本站联系删除。
转载请注明出处:工业自动化冷思考:边缘计算真能扛起预测性维护的大旗? https://www.dachanpin.com/a/tg/55426.html