每次走进某家工厂的中控室,看到墙上那一排屏幕里跳动的数字和线条——嗡鸣的服务器、老旧的CRT显示器(有些居然还在用!)——我都在想,这东西算是工业界的“活化石”了吧?毕竟,监督控制与数据采集(SCADA)的概念,从上世纪60年代就有了。但你说它落伍?真不是。去年去一家半导体厂,他们的SCADA系统处理的数据吞吐量,比某些互联网公司还夸张。这就奇怪了,一个老古董,怎么还能冲在前线?
SCADA的旧魂与新壳
老工控人都知道,最早的SCADA其实就是远程测量+控制。RTU(远程终端单元)通过无线电把水坝水位传回来,值班员瞅一眼,拨个号调整闸门。那时的监督控制与数据采集,核心是“监视”和“控制”,数据?顺便存一下。后来PLC兴起,通讯协议从Modbus打到Profinet,数据量暴增。我见过一套90年代的SCADA,数据库还是用dBase II跑的,查询一次报表得等十分钟。但就是这套东西,稳如老狗,十五年没停过机。

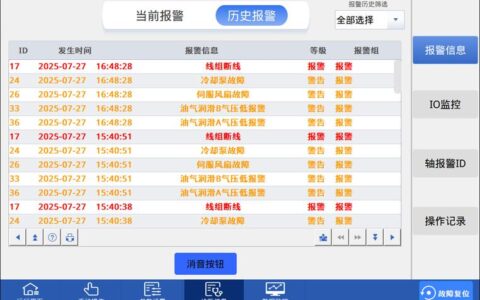
现在的SCADA呢?上云、大数据分析、AI预测……壳换得光鲜。可内里,很多底层逻辑没变。比如说报警管理,十年前被吐槽的“报警风暴”,今天照样淹死新手工程师。我记得帮一家化工厂做优化,一天内SCADA系统弹出三千多条报警,操作员直接无视了——“麻木了。”他说。你看,技术再炫,人性层面的问题还是得靠设计去兜底。
数据洪流下的暗礁

一谈到监督控制与数据采集(SCADA),现在总免不了扯上智能制造。没错,采集上来的数据确实是宝贝。但有个坑很多人不说:数据质量。你想象过吗?一个温度传感器装在振动剧烈的管线上,读数忽高忽低,SCADA系统毫不知情,还忠实地记录着错误数据。最后AI模型训练出来一坨屎。去年我参与一个预测性维护项目,光清洗数据就花了三个月——工业数据不像互联网数据,脏得离谱,而且标注成本极高。 💡 这就是理想与现实的落差。
问:SCADA采集的海量数据到底该怎么治理?难道不能直接灌进大数据平台?
答:千万别!我踩过的雷告诉你,至少要分三步。第一,边缘侧做初步清洗和缓存,别把原始垃圾流量往上送;第二,建立有效的数据模型,明确哪些点需要存储、多少频率,有些冗余的振动数据存一年根本没用;第三,标签体系要统一,不同PLC品牌、不同年代的编码方式混杂,后期根本做不了关联。❗ 否则,你建了个昂贵的智慧工厂数据湖,结果成了数据沼泽。
边缘计算救场?
最近两年,边缘计算在SCADA圈突然火了。说实话,这概念不是新东西,以前的RTU不也是边缘算力吗?不过现在更聪明了——边缘节点能跑轻量模型,就地预警。比如在一家污水处理厂,我在PLC旁边挂了个小盒子,实时分析水泵振动频谱,一旦出现早期故障特征,直接触发本地控制,延迟低于10毫秒。这比传统SCADA傻等着报警阈值强太多了!不过别高兴太早,边缘和中心的协同管理是个大麻烦。版本升级、模型部署、安全补丁……一旦边缘节点上千,运维成本飙升。这就是我为什么总说,技术是一把双刃剑,你追求响应速度,就得忍受分布式管理的头疼。
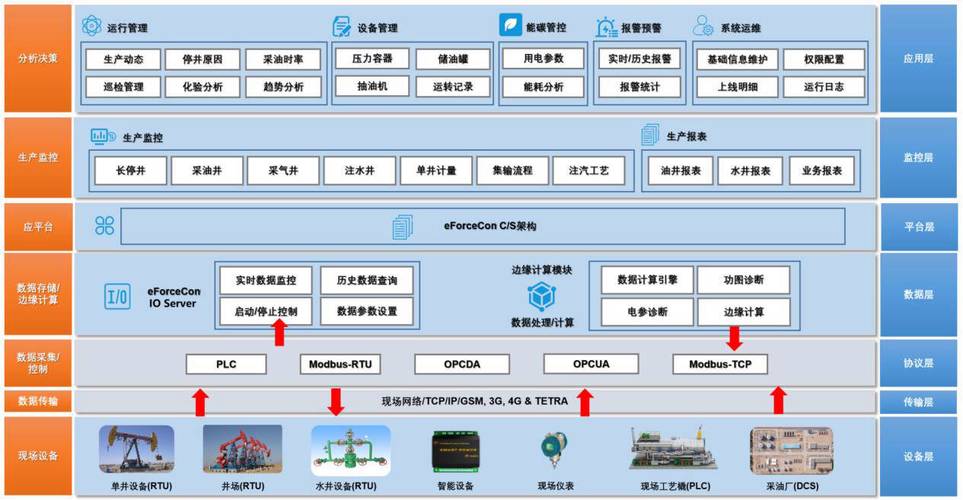
问:既然边缘计算这么好,能不能完全替代云端的集中监控?
答:想得美。边缘擅长实时决策,但不擅长全局优化。比如你要做多个厂区的能耗对比、跨区域的负荷调度,没有中央SCADA的汇聚是不行的。我的经验是:端侧闭环高频控制,边缘侧分钟级优化,云侧做长周期分析和策略调整。 这是三层架构的妥协,也是目前最务实的做法。✅ 记住,没有银弹。
安全,那个没人想谈的幽灵

聊SCADA避不开安全。谁愿意提呢?工厂老板觉得“我们内网隔离,怕啥”,工控工程师觉得“联网是IT的事”。可现实就打脸。去年我朋友所在的汽车装配线,因为一个未经授权的U盘插入工程师站,勒索病毒通过SCADA网络蔓延,几条产线停摆了8小时。损失?几百万。但讽刺的是,事后他们升级了防火墙,却忽略了那个最简单的USB口。所以你看,监督控制与数据采集(SCADA)的安全,往往不是技术不够,而是意识和流程的缺口。 我强烈建议,哪怕只是小厂,也该定期做“红蓝对抗”演练,别等到真出事才哭。
哎,说来说去,SCADA这行就是不断在造轮子和修补轮子。新概念年年有,落地处处坑。但这也是魅力所在——永远有难题等着你去啃。那些看似笨拙的旧系统里,藏着无数工程师的折衷智慧。别急着推翻重来,先理解它为什么存在。
免责声明:文章内容来自互联网,本站仅作为分享,不对其真实性负责,如有侵权等情况,请与本站联系删除。
转载请注明出处:监督控制与数据采集(SCADA):老手的新战场 https://www.dachanpin.com/a/tg/59513.html