工厂里的数据,说实话,一开始就是场灾难。去年我去一家汽配厂,他们厂长拍着胸脯说:“我们上了MES,数据多得很!”结果呢——打开后台,满屏的红黄绿灯报警。我问这批产品的CT(节拍时间)波动为什么这么大?老师傅挠头:“这得问 PLC,我只会看灯。” 数据是有了,可用吗?压根没法用。❗
这就是工业大数据的蛮荒现实。设备每秒钟吐出海量点位数据,振动、温度、压力、电流……但90%的时间我们在“看数据”,而不是“用数据”。更扎心的是,很多数据存储了三个月就被覆盖——因为硬盘不够。花了上百万上的系统,最后成了电子台账。你说,亏不亏?
工业大数据不是“大”就够了
提到“工业大数据”,很多企业第一反应就是上 Hadoop、建数据湖。可往往湖没建成,先把自己淹死了。工业数据的价值不在体量,而在密度和关联性。举个例子:一台数控机床,主轴负载和刀具磨损有隐约的联系,但单独看负载曲线,你什么也看不出。必须把负载数据、振动频谱、工件表面粗糙度、甚至切削液浓度参数跨域对齐,才能拟合出刀具寿命模型。
你猜怎么着?我们团队当时卡在最基础的数据清洗环节。同一台冲压机的压力信号,PLC采到的是“公称力”,传感器传回来的是“应变值”,单位还不统一。仅仅把“力”这一个字段打通,就耗了一个月。⚠️ 工业数据分析师80%的时间不是在建模,而是在洗数据、对齐时间戳——这行真不是光会Python就能干的。
问:中小制造企业连数据基础都没有,怎么玩得转工业大数据?
答:别急着上大平台。我的建议是——从一台设备、一个痛点开始。比如注塑车间总出现缩水缺陷,那就只抓取模温、注射压力、保压时间这三路信号,用边缘计算盒子先做实时监控。浙江有家做开关面板的小厂,花了两万块买了个工业网关,把20台老式注塑机的串口数据传上云,用最简单的阈值逻辑判断异常,三个月就把次品率从8%降到了3%。他们厂长后来跟我说:“以前觉得大数据是谷歌那种公司玩的,没想到我这破机器也能搞。” 💡 关键不是数据大,而是解决问题快。
再说个让人头疼的事儿——数据孤岛。一家钢铁企业,连铸、热轧、冷轧三个分厂的数据居然用三套不同供应商的系统。连铸的钢坯温度曲线想传给热轧工序做均热优化?对不起,得靠人工拷贝Excel再邮件发过去。有一次邮件延误,整批钢坯加热过度,直接损失几十万。后来我们逼着供应商开放API,用中间件把数据流打通,搭建了统一时序数据库,这才实现了全流程温度遗传曲线闭环。那一刻,现场工程师差点哭了——真的。
从“事后诸葛亮”到“事前诸葛亮”——预测性维护的落地真相
工业大数据最诱人的故事就是预测性维护。但听着像魔法,做起来全是细节。
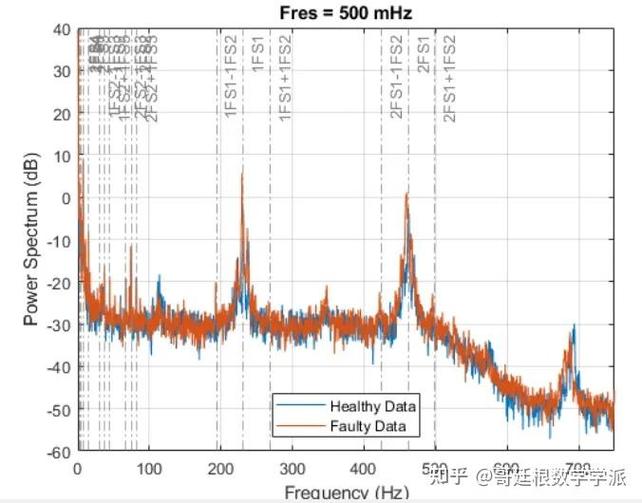
去年我在一家风电叶片厂蹲点,他们想预测模具的真空泵故障。历史数据拉出来一看,就一个开关量:运行/停止。没有电流数据,没有振动数据。就这?还想做预测?后来加装了低成本MEMS传感器,采了三轴振动原始波形,经过FFT转换才发现:泵的轴承保持架磨损会在高频段产生特定的边频带。于是我们用一年的数据训练了一个轻量级异常检测模型,最终提前两周预警了三次故障,避免每一次都长达8小时的意外停线——8小时意味着什么?意味着耽误两套60米模具的灌注,那可是上千万的订单。
问:都说工业大数据要结合AI,是不是非得用深度学习才高级?
答:千万不要被卖算法的忽悠了。工业场景下,统计过程控制(SPC)和物理机理模型往往比黑箱神经网络更可靠。我见过一家泵厂,用简单的多元线性回归,把流量、扬程、电流做关联,就精准判断出叶轮磨损。反倒是另一个项目,花了三个月用LSTM预测轴承剩余寿命,上线后因为换了一批不同牌号的润滑脂,模型全崩。因为你训练集里的数据模式变了。工业现场,可解释性远比复杂模型重要。老师傅需要知道“为什么现在该换刀”,不是只看一个绿灯变红。
有次和一家德国设备商的技术总监聊天,他说了句大实话:“我们卖给你们的设备自带边缘分析模块,可你们居然把它关掉,然后自己重新采集数据训练模型。” 我听了简直想找个地缝钻进去。后来我们反思,确实应该优先利用设备已有的数字化能力。OT(运营技术)与IT的融合,人的经验融合数据的规律,这才是捷径。
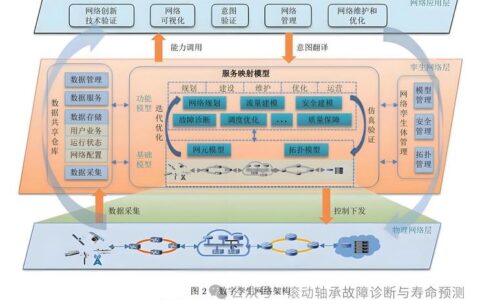
数字孪生:镜像世界的工业级应用
工业大数据往上走,必须谈数字孪生。但千万别以为就是做个3D模型,加点实时数据炫一下。
真正有用的数字孪生,是能“以虚控实”的。比如我们在一条锂电池涂布产线上做尝试:通过采集烘箱各区的温度、风速、浆料粘度数据,建立了一个热场仿真降阶模型,它可以在毫秒级时间里反演烘箱内部的热分布。一旦发现局部热点,系统自动调节风门开度——这比等烘完看到极片干裂再调整,要快得多。这条线一年节省了大约90吨NMP溶剂回收能耗,还减少了极片报废。数字孪生的价值不是好看,是直接用数据流驱动物理优化。
问:我们厂已经上了数字孪生系统,但总觉得像一张华丽的报表,没带来实际效果,问题出在哪?
答:十有八九是数据颗粒度不够。很多数字孪生只接入了设备的运行状态和几个关键指标,刷新率甚至只有分钟级。而真正的实时闭环需要毫秒级的高频数据,并且得把控制参数反向写入PLC。这涉及到工控安全、延迟等一系列问题。建议先从某个单一工序的优化做起,比如热处理炉的温控孪生,打通OPC UA协议,实现毫秒级交互,并设置安全边界——即使孪生系统给出错误建议,也不会超过工艺极限。不要一上来就想做全厂级,会把自己做死。
我还想透露一点:工业大数据最大的挑战,其实不是技术,是人心。车间主任怕透明化之后暴露问题,老师傅怕自动化抢饭碗。有一次我们上了一个OEE(设备综合效率)实时大屏,第一个月就被故意拔掉三次网线。后来我们拉上生产主管单独开会,把数据变成奖金计算的依据——绩效透明化,反而大家抢着报真实数据。所以,搞工业大数据,得懂点车间政治。
好多人问我工业大数据未来怎么样。说实话,我不太关心“未来”,更在乎“明天怎么少停一次机”。铝压铸车间的工人夜里给我发消息,说SPC系统昨天又抓到模具热平衡异常,他们及时换了根热电偶——就这一条消息,让我觉得所有脏活累活都值了。
这就是我们的工业现场。永远在跟噪音、缺失值、看不懂的二进制串斗争。但数据点亮的那一刻,你看见的不再是冰冷的数字,而是机器真实的呼吸。
免责声明:文章内容来自互联网,本站仅作为分享,不对其真实性负责,如有侵权等情况,请与本站联系删除。
转载请注明出处:工业大数据:从数据沼泽到金矿的实战解码 https://www.dachanpin.com/a/tg/55892.html