干这行十五年,见过太多因为设备突然停机引发的闹剧——老板暴跳如雷,维修工满头大汗,生产计划全乱套。你说,这能忍?
不能忍,所以预测性维护算法这玩意儿才火起来。但很多人把它当万能药,最后发现不是那么回事。我踩过的坑,估计比你听过的警报声还多。
算法迷信要不得
市面上吹得天花乱坠的预测性维护算法,什么深度学习、迁移学习、联邦学习,新名词一堆。但据我观察,现场落地成功的,十个里有三个就不错。为什么?
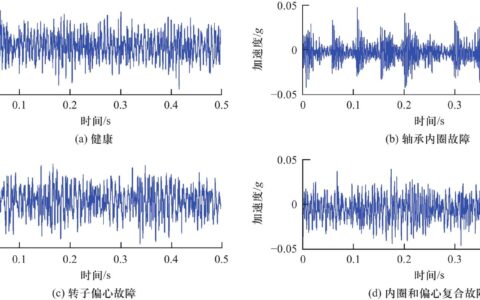
因为数据太烂了。振动传感器装的位置不对,标签全是老张凭经验标注的‘疑似故障’——你告诉模型这是故障?模型一脸懵。有时候数据采了半年,正常样本占99%,故障样本只有两三个,这不叫数据驱动,叫数据误导。❗
还有那些黑箱模型,给出个报警,问它为什么,它没话。老师傅信你才怪。所以我现在更倾向用基于物理模型和统计特征结合的方法,至少能解释。
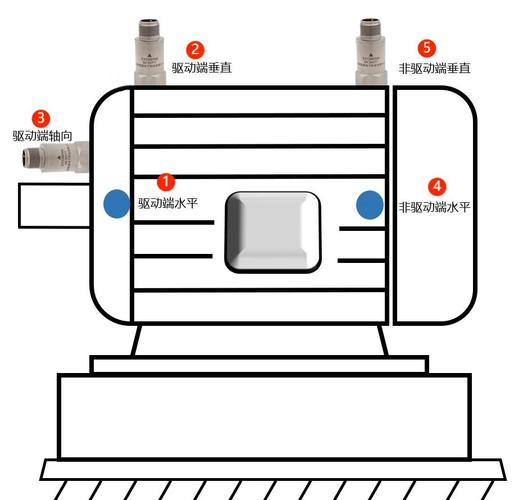
振动、油液、温度——多源数据融合的门道
单独看振动频谱,够不够?说实话,对于旋转设备是基础,但遇到液压系统呢?傻眼了。✅ 我们给一台注塑机做预测,起初只用振动,准确率不到70%,后来加入了油液颗粒度监测和温度趋势,才把预警提前了48小时。这种多源数据融合,不是简单地多接几个传感器,而是要把不同物理量在时间轴上对齐。难处在于,振动是高频采样,油液可能一天一次,怎么对齐?这里就用到时间序列对齐算法,比如动态时间规整(DTW),但工业数据噪声大,DTW也经常罢工。
有时候,一个简单的回归模型比复杂神经网络好用,真的。尤其在工况变化剧烈的时候,神经网络容易过拟合到特定工况,一换产品批次就傻眼。我们后来给机械臂减速器做了个混合模型——卡尔曼滤波估计状态,随机森林做异常检测,故障捕捉率直接升到92%。所以说,别迷信模型复杂度。💡
部署不是终点,运维才是
算法训练好,部署到边缘网关?早着呢。实际环境温差大,传感器漂移,数据分布慢慢变化,这就是概念漂移。你辛辛苦苦调的模型,三个月后可能衰减得像台老爷车。怎么办?
必须建立模型在线更新机制,但又不能全自动——万一把突发故障学成正常怎么办?所以得有人机结合的审核流。我们现在的做法是,每天凌晨自动用新数据微调模型,但阈值保持手动设定,预警先推给手机,维修班长确认后才纳入训练。这样才没出大乱子。
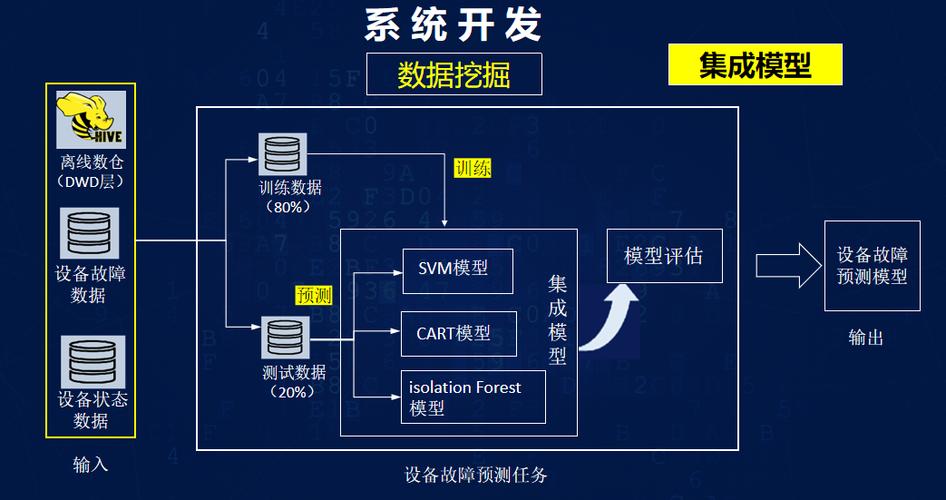
读者QA:小工厂没历史故障数据怎么办?

问:我们厂就几台设备,过去基本没坏过,根本没故障数据。搞预测性维护是不是扯淡?
答:完全不是。这情况太常见了。两个路子:第一,用基于物理退化模型的方法,比如轴承的剩余寿命可以用振动特征频率的幅值趋势来估,不需要历史故障。第二,迁移学习,借别的相似设备的数据。我们给一家小造纸厂做烘缸轴承预测,就是从公开的轴承数据集迁移来的,再结合他们一个月运行数据微调,误报率居然控制在5%以内。当然,前提是你能拿到质量过得去的源域数据。另外,别忽略老师傅的经验规则——把他们的经验代码化,也许就是个简单的if-else,比模型还管用。😄
读者QA:深度学习和传统机器学习怎么选?

问:团队里有几个深度学习背景的,非要用Transformer,但传统统计模型简单,争了半天。到底听谁的?
答:这种争论我经历多了。核心看三点:数据量、实时性要求、可解释性。如果每天就几百条数据,Transformer就是大炮打蚊子,训练时间还长。实时性要求高(比如毫秒级保护),深度学习推断慢,不行。需要给领导解释为什么预警——传统模型如决策树,一目了然。个人经验,设备级的预测(整机健康),隐马尔可夫模型或长短时记忆网络(LSTM)表现稳定;元件级(轴承、齿轮),用支持向量机或孤立森林就够。我们曾试过用CNN分析振动频谱图,结果很炫,但部署在嵌入式系统上,内存直接爆掉,最后灰溜溜换回PCA+逻辑回归。所以,从场景出发,别从论文出发。❗
预测性维护这事儿,说到底不是算法秀场,是实实在在解决停机损失的工具。这两年看到越来越多务实方案,比如基于集成学习的投票机制,或者把知识图谱用于故障根因分析,都挺好。但记住,算法再好,也比不上一支肯配合的运维团队。所以,先搞定人,再搞定代码。
至于未来?可能自监督学习能真正减少对标注的依赖,但今天,我们还是得老老实实洗数据、调阈值。别被PPT忽悠瘸了。✅
免责声明:文章内容来自互联网,本站仅作为分享,不对其真实性负责,如有侵权等情况,请与本站联系删除。
转载请注明出处:预测性维护算法:别再被设备‘背刺’了 https://www.dachanpin.com/a/tg/60426.html